Inference Optimization
Envoy AI Gateway offers smart ways to improve the speed and reliability of your AI/LLM tasks. This section explains how it uses intelligent routing and load balancing to manage inference requests across different backend endpoints efficiently.
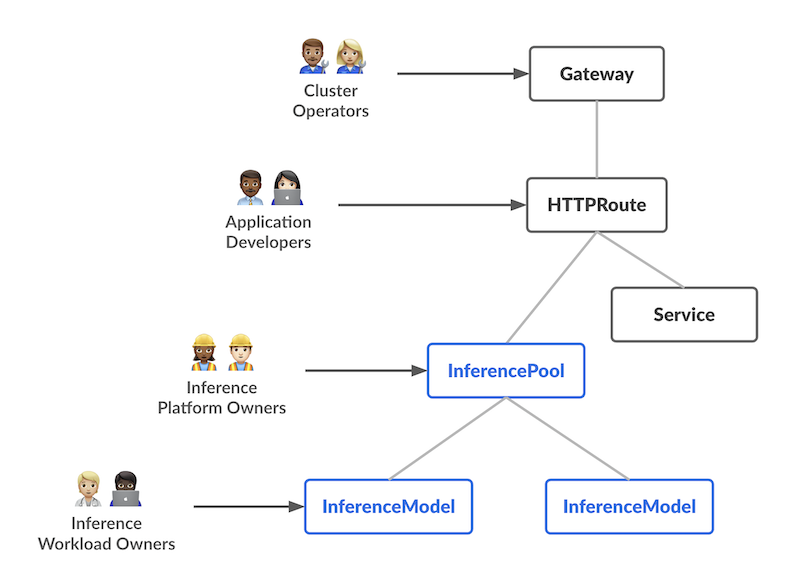
Overview
The inference optimization capabilities in Envoy AI Gateway enable:
- Intelligent Endpoint Selection: Automatically route requests to the most suitable inference endpoints based on real-time metrics and availability
- Dynamic Load Balancing: Distribute inference workloads across multiple backend instances for optimal resource utilization
- Seamless Integration: Work with both standard HTTPRoute and AI Gateway's enhanced AIGatewayRoute configurations
- Extensible Architecture: Support for custom endpoint picker providers (EPP) to implement domain-specific routing logic
Getting Started
To get started with InferencePool support in Envoy AI Gateway:
- Learn about InferencePool Support: Understand the core concepts and benefits
- Try HTTPRoute + InferencePool: Start with basic inference routing
- Explore AIGatewayRoute + InferencePool: Leverage advanced AI-specific features